需求
把 Logseq 上的知识点笔记自动转换为 Anki 的卡片,实现 Logseq 上做知识归类,在 Anki 上做科学复习
Logseq 上的知识笔记:

自动转换 Anki 上的复习卡片效果:
| 卡片正面 | 卡片背面 |
|---|
 |  |
实现分析
整个功能分为三部分:
- markdown 解析
- 标记转换
- Anki 卡片生成
通过 google ,了解有二个开源的 Python 库:
- lepture/mistune:一个快速而强大的Python Markdown解析器,带有渲染器和插件,支持扩展
- kerrickstaley/genanki:通过 Python 3,以编程方式生成 Anki 的 Deck。
借助这两个开源库,整体的实现思路:
- markdown 解析:通过
mistune解析出#anki标记的知识点 - 标记转换:通过正则表达式,把 markdown 的高亮标记
==高亮内容== 转换为 Anki 的填空标记 {{c1::填空内容}} - Anki 卡片生成:通过
genanki生成 Anki 的 Deck。
常规开发方式
有了上面的整体的实现思路,常规开发方式,会采用总分的方式来编写代码,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| ....
class AutoGenanki:
def __init__(self, package_path):
pass
def add_cloze_notes(self, texts):
pass
def write_to_file(self):
pass
class ParseAnkiNote:
def __init__(self, logseq_file):
pass
def start(self):
pass
if __name__ == '__main__':
parse_anki_note = ParseAnkiNote(os.path.join(logseq_journals_path, '2022_08_02.md'))
note_texts = parse_anki_note.start()
auto_gen_anki = AutoGenanki(package_path='./build/output.apkg')
auto_gen_anki.add_cloze_notes(note_texts)
auto_gen_anki.write_to_file()
|
整体过程为:
- 先写框架,忽略细节,提前做好各个模块的衔接
- 逐个填充每个子模块的细节
这种开发模式存在的问题:
- 框架运行成本高:
- 为了让整个框架框架可运行,需要给每个子模块填充假实现
- 构造各种输入数据,用于模拟各自测试 Case
- 子组件的运行成本高:
- 子组件需求依赖整体的框架运行,导致运行速度慢,
- 各子组件需要提交完整代码,不能提交影响运行的代码,并行开发时,会相互影响
结合单元测试的开发方式
通过单元测试来搭建整体的框架,关键是定义好各组件之间的通信接口
项目结构如下:
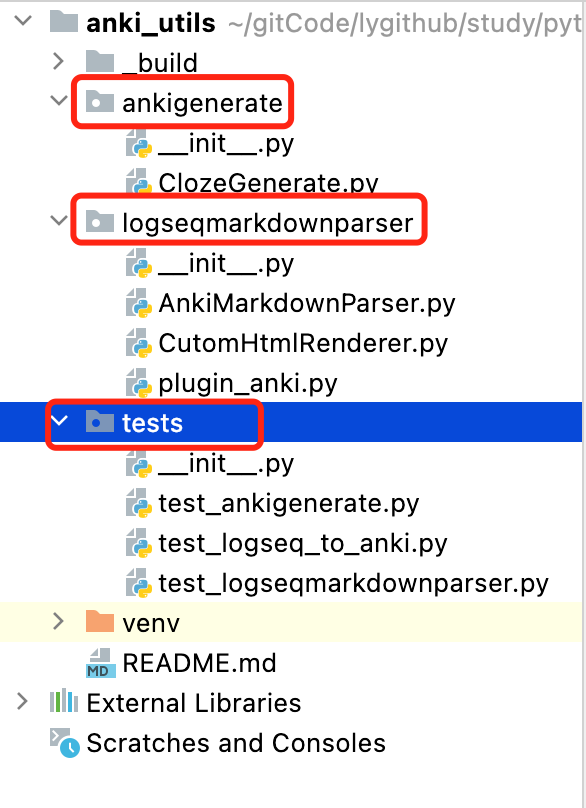
借助单元测试模块,完美的解决上述开发模式的问题。
好处1:子组件支持独立运行,且相互不影响
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| class TestLogseqMarkdownParser(unittest.TestCase):
def test_anki_markdown_parser(self):
md_text = '''
- **Android**
collapsed:: true
- Gradle的Task: #anki
- Task的组成:==由一系列Action (动作)组成的==
- 增加Action的方法:==doFirst、doLast、leftShift、<< ==
- 代码识别:
` ` `
task myTask1 {
println "123" ==配置阶段执行的配置代码==
}
` ` `
- python
- pyhton字典访问元素: #anki
- dict[key],如果key不存在,==抛出 KeyError 异常==
- dict.get(key),如果key不存在,==返回默认值 None==
- 指定key不存在时的返回值:==dict.get(key, 0.0)==
'''
html_text = AnkiMarkdownParser.parse_md_to_html(md_text)
print(html_text)
self.assertNotIn("#anki", html_text)
self.assertNotIn("==", html_text)
self.assertIn("{{c1::", html_text)
cloze_dict = AnkiMarkdownParser.html_to_dict(html_text)
print(cloze_dict)
self.assertTrue(cloze_dict.__contains__('Android'))
self.assertTrue(cloze_dict.__contains__('python'))
|
好处2:正则表达式等需要独立测试的核心逻辑,可单且快速的运行并测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| class TestAnkiGenerate(unittest.TestCase):
def test_code_one_line(self):
code = '''
task myTask1 {
println "123" ==@1==
pringln "456" ==@2==
pringln "23984" ==@3==
}
'''
def tag_text(matched):
return '{{c1::' + matched.group(1) + '}}'
new_code = re.sub(r'==(.+?)==', tag_text, code)
print(new_code)
self.assertNotIn("==", new_code)
self.assertIn("{{c1::", new_code)
|
好处3:单元测试的用case就相当于使用文档,不用额外编写使用文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| class TestAnkiGenerate(unittest.TestCase):
def test_cloze_gen(self):
cloze_gen = ClozeGenerate('../_build')
cloze_dict = {
"Android": [
"cloze卡片1",
"cloze卡片2"
],
"阅读": [
"cloze卡片1",
"cloze卡片2"
]
}
cloze_gen.add_cloze_notes(cloze_dict)
filepath = cloze_gen.write_to_file()
self.assertTrue(os.path.exists(filepath))
|
注意:尤其是 python 这种弱类型语言,或者函数有字典参数的功能,好处3的意义更大
好处4:后期功能迭代时,通过阅读单元测试,可以快速了解子组件的各种边界条件,通过运行历史的单元测试,又可以提升代码迭代的质量
下面的代码是扩展多行填空卡片支持的迭代需求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| class TestAnkiGenerate(unittest.TestCase):
def test_code_one_line(self):
code = '''
task myTask1 {
println "123" ==@1==
pringln "456" ==@2==
pringln "23984" ==@3==
}
'''
def tag_text(matched):
return '{{c1::' + matched.group(1) + '}}'
new_code = re.sub(r'==(.+?)==', tag_text, code)
print(new_code)
self.assertNotIn("==", new_code)
self.assertIn("{{c1::", new_code)
def test_code_multi_line(self):
code = '''
task myTask1 {
====println "123"
pringln "456"
pringln "23984"====
====println "2335"
println "35894"====
}
'''
def tag_text(matched):
return '{{c1::' + matched.group(1) + '}}'
new_code = re.sub(r'====((?:.|\n)+?)====', tag_text, code)
print(new_code)
self.assertNotIn("====", new_code)
self.assertIn("{{c1::", new_code)
|
总结
之前我一直不愿意写单元测试的原因有两个方面:
- 单元测试应该是在功能开发结束后才写的,这时再去写单元测试,就会影响功能交付的时间
- 单元测试的代码覆盖率不高,无法做 100% 的覆盖,导致无法节省人工测试
我们无法做到《Google 软件测试之道》里提到的“开发和测试必须同时开展,写一段代码就立刻测试这段代码”程度,但可以按一个角度来考虑,单元测试能否提升开发效率:
- 功能开发阶段:通过单元测试,减少运行成本,提高并行开发效率,提高沟通效率
- Bug修复阶段:通过单元测试,可以不断补全问题模块的测试边界,持续改善后续迭代的代码质量
- 功能迭代阶段:通过单元测试,快速了解代码的使用方式,Api如何传参,各种使用场景,通过运行历史的单元测试,减少历史问题重复发生
